
Entangled News Streams
Entity-centric Implicit Networks for Entangled News Streams
Reading it in the paper in the morning is a common idiom for catching up with the news that is becoming increasingly less applicable. Putting aside the obvious departure from printed news, both the temporal aspect and the grammatical singular are less and less accurate. News are not reported and consumed in the morning but in a constant news cycle throughout the day, published by a multitude of news outlets with varying degrees of reliability, political bias, and overlapping content. It is these entangled streams of news that the reader has to wade through to stay informed.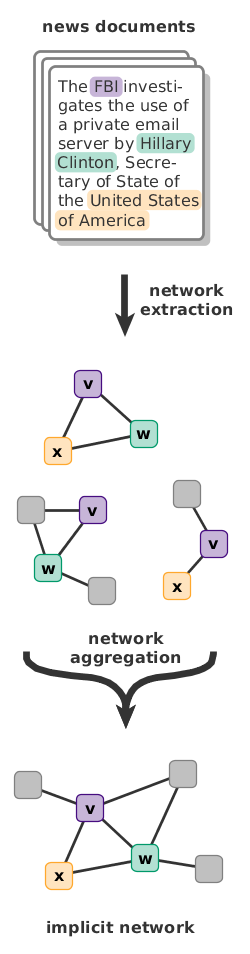 In the context of news, the so called Five Ws of Who?, When?, Where?, What?, and Why? are questions of central importance that serve the journalist and the reader in uncovering news. Naturally, these questions put an emphasis on entities as pivotal components of news. In information retrieval, this is reflected in the definition of an event as something that happens at a given place and time between a group of actors, which highlights the central role of entities for inducing structure in the unstructured texts of news articles.
In the context of news, the so called Five Ws of Who?, When?, Where?, What?, and Why? are questions of central importance that serve the journalist and the reader in uncovering news. Naturally, these questions put an emphasis on entities as pivotal components of news. In information retrieval, this is reflected in the definition of an event as something that happens at a given place and time between a group of actors, which highlights the central role of entities for inducing structure in the unstructured texts of news articles.In large entangled news streams, far more than one news article tends to be required to retrieve the full picture. However, a lot of information is replicated between or even within individual news streams and thus redundant. To make the news content accessible to users, a central step is thus its aggregation along some dimension(s), such as time, location, or participating entities.
When considered for contrastive explorations of content, the established aggregation approaches suffer from two critical drawbacks: the limited number of aggregation dimensions and the aggregation granularity level. No approach covers the entirety of available aggregation dimensions and it is indeed questionable whether an aggregation along all dimensions at once is realistically possible. Perhaps even more critically, the results tend to be coarse structures such as clusters of documents, topics, or events. However, since events are commonly defined as composite mentions of (named) entities, they form the stitching points between individual news streams. Thus, it makes sense to consider a dynamic aggregation on the level of entities. After all, we consume news about people, organizations, or locations of interest and follow them over time and in different contexts.
To address this fine-granular aggregation need, we introduce entity-centric implicit networks as a representation of entangled news streams. Based on the concept of implicit entity networks for static document collections, we include entity relation information, a spatial and two temporal dimensions (temporal expressions and publication metadata), and the context of mentions in a comprehensive framework for entity-centric analyses. On the technical side, we addresses the inherent scaling issues of entangled news streams by utilizing efficient entity-centric queries to localized graph substructures. Furthermore, the implicit representation serves as an (inverse) index for retrieval tasks without requiring the storage of proprietary news article content. On the application side, our model provides a more fine-grained and versatile representation of entangled news streams than any previous approach. Instead of utilizing document- or event-centric indexing, we focus on the level of entities and contexts and use them as stitching points between individual news threads. The resulting model supports a wide range of tasks, including entity-centric topic and event extraction and tracking, contextual search, contrastive source comparison, and exploratory visualizations of the underlying streams.
News Article Network Data
We extracted an entity-centric implicit network from a set of 127,485 English news articles. By following the RSS feeds of the news outlets, we covered CNN, LA Times, NY Times, USA Today, CBS News, The Washington Post, IBTimes, BBC, The Independent, Reuters, SkyNews, The Telegraph, The Guardian, and Sidney Morning Herald to extract political news between June 1, 2016 and November 30, 2016.
We annotated named entities with the Ambiverse text to knowledge API, sentences and parts-of-speech with Stanford Core NLP, and temporal expressions with HeidelTime before constructing the network. The final network contains 27.7k unique locations, 72.0k actors, 19.6k organizations, 5.7K dates and 329k terms (i.e., remaining non-entity words). The network data consists of one edge list, which is structured in blocks of:
- source ID: String ID of the source node (Wikidata ID or term label)
- source type: Type of the source node {loc, org, act, dat, erm, page, or sentence)
- target ID: String ID of the target node (Wikidata ID or term label)
- target type: Type of the target node {loc, org, act, dat, erm, page, or sentence)
- publication date: Publication dte of the article the edge was extracted from
- mention distance: distance in sentences between the mentions of the two nodes
- [context]: 300-dimensional context embedding vector of the context window
- [verbs]: list of all verbs in the context window
The last two entries (context and verbs) are only present if the type of the target node does not equal page or sentence.
Additionally, we include a list of all articles that were used in the construction of the network, along with the source URLs. Note that we cannot provide the article content. The file is structured in blocks as follows:
- article ID: The ID of the article in the network and ground truth data
- article outlet: The news outlet that published the article
- publication date: Date at which the article was published
- title: Title of the article
- URL: URL of the article
Since most of our implementation is using a MongoDB to store and index the data, we also include the code of a Java program that can be used to import the data into a MongoDB instance. Note that the data set is large due to the included vector embeddings of the context.
[zip] Download implicit network data (6.8 GB compressed, 179 GB uncompressed).
News Event Ground Truth Data
For our evaluation of the event completion task, we extracted ground truth events from the Wikipedia Current Events portal. Note that only those events are included that (1) were published within the time frame of June 1, 2016 and November 30, 2016, and (2) are covered by at least one article in our document collection as denoted by the source annotation in Wikipedia. The data consists of two files.The events file contains 97 individual news events in JSON format that could be linked to articles in the collection. The items file contains all individual evaluation items that can be constructed from these events (for details, please refer to the article). Relevant fields in the data are:
- content: full text of the event description
- category: category of the event
- date: date on which the event occurred
- source_links: array containing the URLs of source
- source_article_id: internal integer ID of the article (with the prefix "p", these correspond to document IDs in the network data)
- entities: Wikidata identifiers of all entities in the event description
- neClasses: named entity classes of the entities (LOC, ORG, or PER)
- terms: non-entity terms in the event description
- context: context vector of the event description
- verbs: verbs that occur in the event description
- verb_context: context embedding of the verbs in the event description
The items file contains additional attributes for the evaluation process that correspond to the target entity (the entity to predict) and all remaining entities.
For the evaluation procedure in our implementation, the data should be contained in a MongoDB. For instructions on how to import the data from JSON files, see the accompanying readme file.
[zip] Download ground truth data (5 MB compressed, 16 MB uncompressed).
Implementation & Code
The implementation will be available shortly. If you would like to be notified once that happens, please let us know.
For compatibility with our implementation, we provide a clear text version of the pre-trained 300-dimensional word2vec embeddings from GoogleNews-vectors-negative300. In contrast to the original encoding, the binary data is converted to text data for ease of using with our exploration code. Note that these can be replaced by any similarly structured word embeddings. We recommend using less than 300-dimensional embeddings for use with larger corpora.
[zip] Download pre-trained embeddings (2.9 GB compressed, 8.6 GB uncompressed).
Publications & References
The paper that describes the above approach was presented at the Journalism, Misinformation and Fact Checking track at The Web Conference 2018.
- Andreas Spitz and Michael Gertz.
Exploring Entity-centric Networks in Entangled News Streams.
In: Proceedings of the 27th International Conference on World Wide Web Companion (WWW), Lyon, France, April 23-27, 2018
[pdf] [acm] [bibtex] [slides]